Apache Airflow - The famous Opensource Pythonic general-purpose data orchestration tool. It lets you do a variety of things. The open-ended nature of the tool gives room for a variety of customization.
While this is a good thing, there are no bounds in which the system can or cannot be used. Resulting in wasting a lot of time in scaling, testing and debugging when things aren't set properly.
You can also use this post to convince your management Why is it taking so much time? why do you have to set standards and ground rules for your data projects? Jarek approved and recognized this blog post in Airflow's slack channel.
The Dev & Ops Team
Using Airflow for your Data team means you need a good mix of Python and DevOps skills.
The Python Devs would take care of pipelining and debugging the code that runs on the pipelines whereas the Ops team ensures the infrastructure stays intact, is easy to use and debug as per need.
A badly written pipeline code can be resource hungry and the Ops teams will have no control over it. Similarly, a resource-constrained breaking infrastructure doesn't give a smooth development experience for DAG authors.
It is important for these teams to work hand in hand but also knows where their lines of responsibilities are.
Infrastructure
IaC
You will always spin up a new airflow environment. By default, any data team will need at least 3 Airflow environments - Dev, Test, and Prod. Factoring in the teams and projects you are going to need more environments. If not today you might need it 6 months down the line.
Code is the ultimate truth.
The maximum automation I've seen is bash scripts stitched together. That only gives you info about Airflow configs and not the infra configs. EC2 or EKS? Loadbalancer? DNS mapping?
There is a good chance that the DevOps engineer who set this up might move companies or to a different project. All that the teams are left with are a bunch of bash scripts and commands to run.
Instead of investing time in documenting the commands, you can spend that time automating it with Terraform or similar IaaC tools
CI/CD Pipeline
Often you will be working with multiple dag authors. It is important to set up a system that provides them with a quick turnaround time to test and deploy their features
Environments, where dag authors are doing a git pull on the server directly, aren't going to cut it. There were also cases where you have dag authors fighting over the package versions they want for their PythonOperator to run.
There are three ways to get your DAGs into the Airflow instance
Doesn't matter what method you choose the underlying idea is to have these update your Airflow instance when the developer is ready to do so.
Not Customizing
Airflow comes with a tonne of tools, tweaks and configs. One pattern I see commonly is following an infra guideline blindly and not customizing it to your needs.
Here are a few things to take into account
How many environments would you need?
How many DAGs are going to run?
What infra tools work the best for our team?
What are our peak schedules, will our resource allocation withstand it?
What is it going to cost?
Even if you are building a POC keep all of these things in mind. Some teams are expected to go from POC to prod in a matter of weeks
Over Optimizing
You don't need a complicated infrastructure unless you're running 100s of dags with 100s of tasks. Pick a pattern and scale on demand.
Kubernetes lets you scale the best. You can run 3 pods one for each component and scale it as you need.
But there are also cases where Airflow instances run happily on consolidated EC2 for years
Pick your poison based on your current and projected needs.
Versions
Using old Airflow Version
Airflow made 12 releases in 2022(1 release per month). That's crazy! I know, It's hard to keep up. But if you are starting fresh.
Perks of using the latest airflow version
What about new bugs?
That's a part of using opensource technologies. You get to jump in and help the community fix them.
But if you're cautious, maybe try 2 versions down. That way, some show-stopping bugs can be found on Github issues.
Following old Docs/Blogs
Airflow has been around for years now. There are a variety of Guides, tools, and blogs out there. Some of them are so old that it doesn't do justice to the overhaul Airflow got in 2.0+.
One developer created a whole plugin following a blog, but what they should've used is a provider. The support for plugins as a provider was removed after 1.10.x versions. The result? 2 more weeks of development and testing
Even if you're using the Airflow docs page, ensure you are on the right version. The same goes for providers. Providers are also constantly updated and optimized to support the latest features of the integrating system.
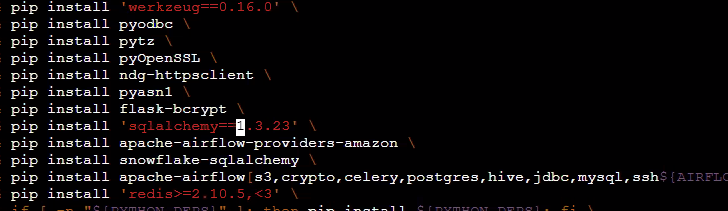
Not Freezing Library Requirements
Those pip libraries with no specific version tagged are timebombs waiting to tick when you need the environment up and running 6 months down the line. Always enforce developers to tag all requirements with their respective versions.
Airflow Components
Running scheduler as a part of the webserver
The scheduler is the heart and brain of Airflow. The practice to run Scheduler as a part of the webserver was propagated by Puckel Docker images and still sticks around in most code bases.
The script suggests you run both webserver and scheduler on the same machine for LocalExecutor and SequentialExecutor This might still work well for small scale, as you add more dags, the scheduler will need more memory and computation to spin up your tasks, irrespective of the Executor you use.
Right Executor for the Job
Airflow provides a variety of executors. Choosing the right one depends on a lot of factors scale, team size, and dag use case.
I have a separate post on this checkout Pros and cons of using different Airflow executor
Database
Using sqlite.db. It's not production friendly. The 1st thing I do with any Airflow installation is to change it to Postgres. (or MySQL)
Running Database in a docker container or Kubernetes pod is not advised. Tutorials advise them to get things up and have consistent results for the reader. A quick alternative is to set up an RDS or managed database and use it. Services like supabase give you readily available Postgres
Not Persisting Logging
You need to track two kinds of Logs for Airflow. The logs of Airflow components and The logs from running your pipelining code. Not having access to either one of those will create problems while debugging down the line.
"Our nightly run failed and we have no idea why" is how it starts, on investigating we will find that the scheduler pod that was responsible for those spin ups evicted with all the logs associated with it.
Large-Data processing
Apache Airflow being the famous Opensource general-purpose data orchestration tool, lets you do a variety of things and gives room for lots of customization.
Yes, it is general-purpose. Yes, you can do a variety of things. But processing GBs or TBs of data is not Airflow's game. Often teams use Pandas to write small transformations or run queries, but that practice can propagate to large datasets as well.
The workaround
Use the right tools for the right job like spark or Hadoop
Remember Airflow is not an ETL tool, it is a Trigger -> Track -> Notify tool
Top-Level Python Code
Airflow DAGs are Python-first. You can write any kind of Python code to generate DAGs
While these may look like a fair thing to do, these pop up as huge blockers as the infrastructure scale.